OpenAI API 学习指南
获取 OpenAI API 密钥
获取 OpenAI 账号
如果您已经使用过 ChatGPT,那么您的 ChatGPT 账号即为 OpenAI 账号,直接使用即可。
如果您尚未注册,可以在相关网站注册账号。不过,由于国内访问限制,注册过程可能较为复杂,网上有众多注册教程可供参考。如果觉得麻烦,也可以选择在某些平台上购买账号,或者直接获取一个可用的 API 密钥。
获取 OpenAI API 密钥
登录 OpenAI 后,移动鼠标至页面左侧,可以看到一个弹出的侧边栏。
点击侧边栏中的“API Keys”,进入 API Keys 页面。
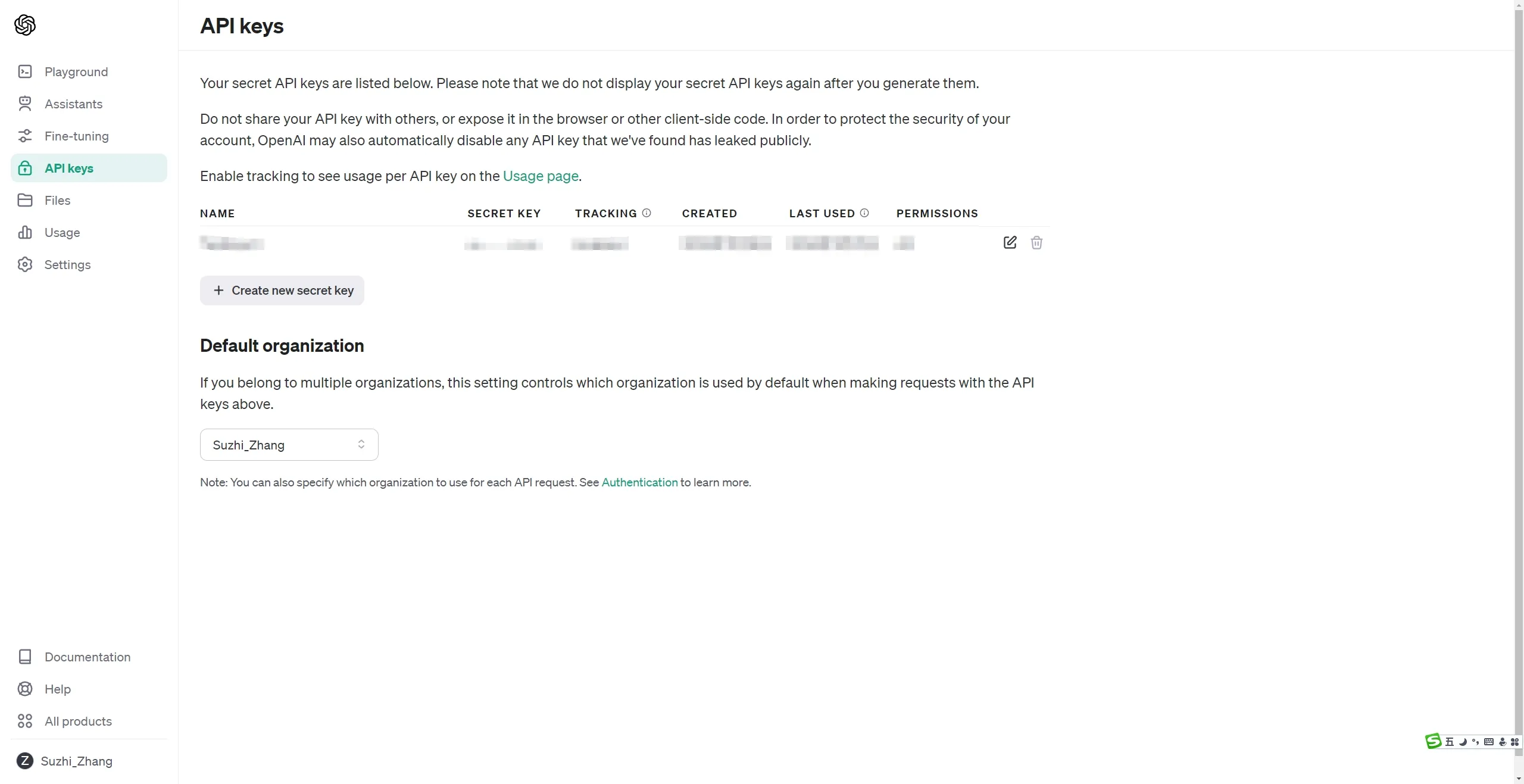
在此页面,可以管理(创建、删除等)所有 API 密钥。
点击“Create new secret key”进行新密钥的创建,给密钥命名并确认。此时将会弹出一个对话框,显示新创建的密钥。务必立即保存这个密钥,因为关闭对话框后就无法再次查看。
保存完成后,点击“Done”,便可在该页面查看到新创建的 API 密钥。
获取 API 使用额度
额度查询
点击侧边栏中的“Usage”进入使用页面。该页面左侧显示每天的花费,右侧显示当前可用额度。
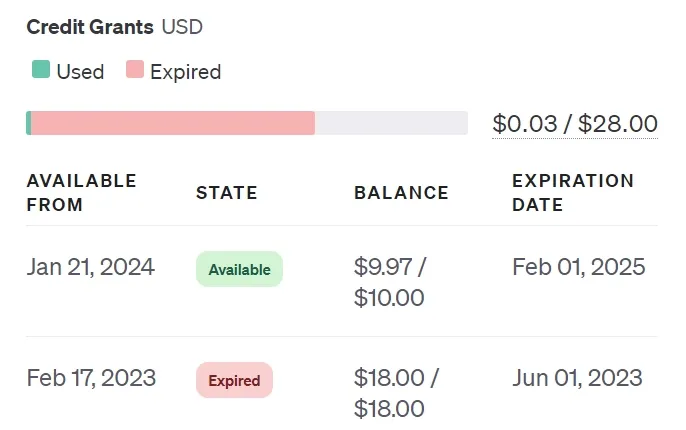
右侧的 Credit Grants 区域分为三种颜色:灰(未使用)、绿(已使用)、红(已过期)。当额度未使用(灰色状态)时,才能成功使用 API 密钥进行调用。
额度充值
点击侧边栏中的“Setting”,再选择“Billing”进入账单页面。在此页面,可管理与充值相关的事项。
充值前需添加一种付款方式,点击 Payment methods 进行管理。由于网络限制,国内 Visa 卡可能无法使用,可以考虑使用国外的卡,或者网络虚拟卡。
添加支付方式后,返回 Overview 页面,点击 Add to credit balance 进行充值。充值完成后,返回 Usage 页面即可查看可用额度的变化。
Python 使用测试
配置 Python
确保 Python 版本在 3.7.1 以上。为了方便使用,您可以使用 Anaconda 创建虚拟环境。
安装 OpenAI 库
设置您的 API 密钥
OpenAI 会默认从环境变量中寻找 “OPENAI_API_KEY”。以下是两种设置方式:
- 为所有项目设置
在系统环境变量中添加 OPENAI_API_KEY(可以通过 Win 键搜索环境变量打开该页面)。
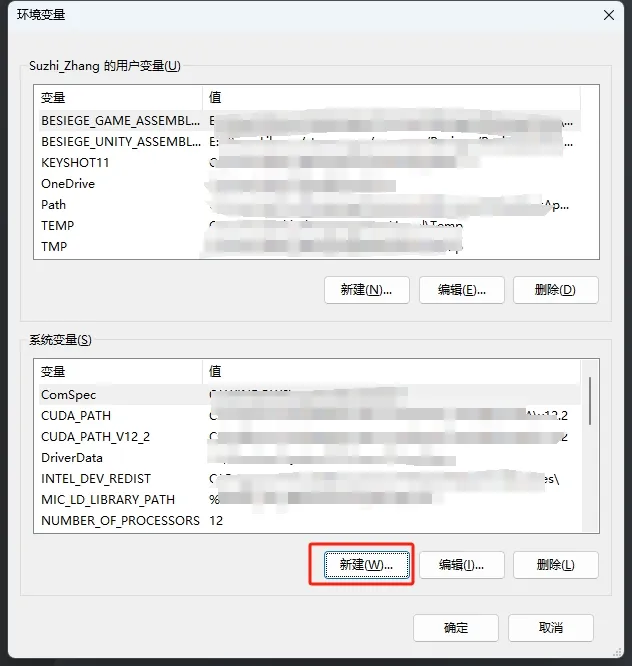
添加完成后,可以在命令行中运行 echo %OPENAI_API_KEY% 检查设置是否成功。
python
from openai import OpenAI
client = OpenAI()
- 为单个项目设置
在项目文件夹中创建.env文件(如需使用 git 进行管理,请忽略该文件),输入:
OPENAI_API_KEY=(您的密钥)
运行测试时,如果没有产生错误则表示设置成功。
发送请求测试
请求一个简单的 gpt-3.5 chat:
python
import os
import dotenv
from openai import OpenAI
dotenv.load_dotenv()
client = OpenAI(
api_key=os.environ.get("OPENAI_API_KEY"),
)
发送请求
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."},
{"role": "user", "content": "Compose a poem that explains the concept of recursion in programming."}
]
)
打印回复
print(completion.choices[0].message.content)
现在,可以在 使用页面 查看这次请求的费用和 token 使用情况(可能有延迟)。
功能介绍(以 Python 为例)
文字生成
官方教程:文字生成指南
可以理解语言(GPT-4 也能理解图像)并返回文本。
python
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
主要输入是 messages,即一个 message 对象的列表。每个 message 对象由 role(system、user 或 assistant)和 content 组成。通常对话以一个系统信息开头,接着是多个用户或助手信息。
- system(可选):用于设置 AI 的行为;
- user:AI 需要回应的信息;
- assistant:之前 AI 的回复,用于给 AI 提供参考。
在每个回复中,都会有 finish_reason:
- stop:API 返回信息完成,或触发了 stop 参数;
- length:达到 max_token 参数或模型限制;
- tool_call:模型决定调用工具;
- content_filter:由于内容过滤器被隐藏的内容;
- null:请求未完成。
图像输入
GPT-4 的视觉版本可以理解图像。在用户消息的内容中,添加类型为 image_url 的图像网址即可。
可以同时添加多个图像,并通过 detail 参数控制模型处理图像的方式。
- 默认值为 auto;
- low 时使用 512*512 的低质量图像;
- high 时模型会先查看 512 的低质量图像。
JSON 格式输出
要让模型始终返回 JSON 对象,可以设置 response_format 为 { "type": "json_object" }。
在输出的 JSON 前,请检查 finish_reason,若为 length 则结果可能受到截断,不应使用。
图像生成
